Inspiro 2.0: Raziskovalno-umetniški projekt o pismih iz preteklosti
Raziskovalni dnevnik projekta:
Povezave med čustveno obarvanostjo pisem in uspešnostjo transkripcije z uporabo HTR metod: kako zveni (ne)berljivost čustev?
Projekt obsega tri faze:
A. V prvi fazi se projekt osredotoča na uporabo metod digitalne humanistike, tj. na samodejno prepoznavanje besed (ang. ATR - Automatic Term Recognition).
Cilji te raziskovalne faze so:
- prehod iz ročnega na samodejno transkribiranje pisem;
- pospeševanje procesa transkripcije;
- vnos novih pisem v elektronsko zbirko Pisma.

B. Druga raziskovalna faza se navezuje na rezultate, ki smo bili pridobljeni z digitalno metodologijo v prvi fazi, pri čemer številčne vrednosti umešča v kontekst obstoječih raziskav intime v pismih. Cilj te faze je namreč preveriti, ali je vsebina pisem (predvsem z vidika njihove čustvene obarvanosti) povezana z uspešnostjo strojnega branja rokopisnega besedila. Na ta način bo mogoče preveriti hipotezo o rokopisu kot tipu samocenzure na primeru posameznih avtoric iz baze.
Cilj te faze je tudi teoretska kontekstualizacija rezultatov strojnega branja z navezovanjem na že obstoječe študije, ki izhajajo iz raziskav na projektih Raziskovalnega centra za humanistiko Univerze v Novi Gorici, kot sta študiji dr. Primoža Mlačnika Epistolarne intimnosti: razmerja med pisemskim prijateljstvom, ustvarjalno samocenzuro in žensko emancipacijo in dr. Ivane Zajc »Nucamo vsaj nekaj žensk, ki se zanimajo za poezijo«: samoreprezentacije avtoric iz obdobja moderne v pismih.
C. V tretji fazi projekta empirične in teoretične rezultate prenašamo v novo dimenzijo – zvok z namenom predstavitve (ne)berljivosti pisem v mediju, ki je drugačen od besedila.
Cilj zadnje faze je razbijanje funkcionalne fiksiranosti na en medij oziroma eno plast percepcije pisem in metaforično prevajanje emocij iz besedila v zvok, da bi se poustvarila njihova vsebina. Zvok pisem bomo programirali s pomočjo številčnih vrednosti iz prve faze dela, pri čemer bomo ohranili koordinate znanstvenega dela našega raziskovanja v jedru umetniške predstavitve čustvenosti vsebine pisem.
Potek procesa dela
Zapiski študentke ob raziskovanju
A. PRVA FAZA: Od ročne transkripcije do uspešnega modela za samodejno branje
Ker sem doslej uspešno pripeljala prvo fazo do konca, se bom na kratko zadržala pri konkretnem delovnem procesu, izzivih, postopkih in rezultatih, do katerih sem prišla.
Do začetka projekta Inspiro je elektronska zbirka Pisma Raziskovalnega centra za humanistiko že vsebovala nekaj več kot 2000 pisem – torej pisem, ki so zbrana, transkribirana in vnesena v spletno bazo, nekatera tudi skenirana. Baza vsebuje tako transkribirana besedila kot tudi metapodatke in faksimile. Ta baza je predstavljala osnovo za več raziskav, nedavno pa je izšla tudi knjiga Ljubim lepa pisma: dopisovanja avtoric slovenske moderne. Ker je že sama sprva zbirka nastala kot študentski projekt, projekt Povezave med čustveno obarvanostjo pisem in uspešnostjo transkripcije z uporabo HTR metod pomeni neposredno nadaljevanje prej uspešno izvedenih študentskih iniciativ in raziskav.
Čeprav je veliko pisem, zahvaljujoč delu številnih raziskovalk in raziskovalcev, študentov in prostovoljcev, že dostopnih v bazi, je treba poudariti, da so bila vsa pisma transkribirana ročno, kar zahteva precej časa (razen v redkih primerih, ko so pisma tipkana in ne rokopisna).
Ker se lahko zbirka obogati s transkripcijo novih pisem, sem pri konceptualizaciji projekta izhajala iz tega, da bi avtomatizacija postopka transkripcije kot prvi cilj projekta pomenila pomemben korak k izboljšanju postopka vnosa novih pisem.
V prvi fazi sem imela zato več mikrociljev:
- testiranje programov za HTR in izbira programa za delo;
- izbor pisem in zbiranje faksimilov;
- predobdelava faksimilov – optimizacija fotografij/PDF-jev za delo v programu;
- usposabljanje za delo v eScriptoriumu (usposabljanje na poletni šoli v Berlinu);
- iskanje ustreznega modela za branje rokopisov v slovenščini;
- treniranje modela za rokopise v slovenščini;
- preverjanje uspešnosti novih modelov.
Uresničitev mikrociljev v prvi raziskovalni fazi vodi k širšima ciljema prve faze: pospešitvi procesa transkripcije in vnosu novih pisem v bazo.

Z raziskovanjem dostopnih orodij za HTR sem na podlagi števila uporabnic in uporabnikov ter nekaj preglednih člankov (Eleftheriadi 2025, Thompson 2021) izbor zožila na dve dostopni platformi – Transkribus in eScriptorium. Obe orodji služita za samodejno prepoznavanje in transkripcijo rokopisnih besedil, kakor tudi za prepoznavanje in analizo postavitve strani (layout), npr. vrstic, stolpcev, besedilnih blokov itd. Transkribus ima dostopne modele za številne jezike in omogoča tudi učenje lastnih modelov. Največja omejitev Transkribusa pa je v tem, da se modeli, ki so ustvarjeni ali trenirani preko Transkribusa, ne morejo izvoziti in shraniti v obliki, ki bi bila uporabna zunaj platforme.
Na drugi strani eScriptorium uporablja Kraken engine za OCR in HTR – Kraken je fleksibilen in ne temelji na predpostavkah, temveč se prilagaja učenju z npr. raznolikimi postavitvami besedila (tudi smeri besedila) in nestandardnimi rokopisi, kar je posebej uporabno za zbirko Pisma, ki vsebuje veliko razglednic, besedil, pisanih v različnih smereh, z različnimi pisavami (cirilico in latinico) ter jeziki. Poleg tega eScriptorium omogoča uporabnicam in uporabnikom ročno segmentacijo, popravljanje napak in ustvarjanje ground truth podatkov, na podlagi katerih se nato lahko trenirajo in uporabljajo lastni modeli. Največja prednost eScriptoriuma je njegova odprtost: novi trenirani modeli se lahko izvažajo, kar je precej prilagodljivejše in praktičnejše za dolgoročno delo.
Iz teh razlogov sem se odločila primarno za eScriptorium, saj omogoča nadaljnje treniranje in shranjevanje modelov za več različnih pisav (avtorjev in avtoric), ki jih imamo v zbirki Pisma.
Druga naloga – izbor pisem in zbiranje faksimilov – je bila primarno vezana na neposredno delo z elektronsko zbirko ter na posvetovanja z mentorico dr. Ivano Zajc in glavno urednico Elektronske zbirke Pisma dr. Katjo Mihurko. V tej fazi smo izbrale skupno 40 pisem, razdeljenih v skupine po osem pisem naslednjih avtorjev in avtoric: Zofke Kveder, Vide Jeraj, Marice Nadlišek Bartol, Josipa Murna in Ivana Cankarja.

Na podlagi že dostopne tematske klasifikacije pisem v zbirki (ki omogoča lažje iskanje po temah) smo pisma razdelile v dve enaki skupini – na skupino 20 čustvenih pisem (ki obravnavajo teme, kot so: žensko prijateljstvo, žensko-moško prijateljstvo, moško prijateljstvo, ljubezen, sreča, spolnost, erotika itd.) in na kontrolno skupino 20 pisem navedenih avtorjev, ki se dotikajo naključnih tematik (kultura in umetnost, rastlinski svet, zdravje, finance, vreme, hrana itd.). Obe skupini imata približno enako število znakov (med 8500 in 9000).
Ta razdelitev bo pomembna za drugo in tretjo fazo projekta, tj. za preverjanje hipoteze o povezanosti čustvene nasičenosti pisem in uspešnosti branja s pomočjo HTR metod.
V naslednji fazi dela sem pripravljala zbrane faksimile za delo v eScriptoriumu. To pomeni predvsem tehnično delo: zviševanje kakovosti fotografij na najmanj 300 dpi ter izboljševanje kakovosti, tj. nastavitev grayscale(odstranjevanje barve, kadar je smiselno), noise removal (nekatera pisma so bila porozna), kontrast ipd. Za to vrsto posegov so uporabna npr. orodja Pillow, Image Magick, Leptonica ipd. Kljub temu je bila večina faksimilov dovolj kakovostna, zato fotografij ni bilo treba posebej podrobno procesirati.
Čeprav je eScriptorium dostopen in ima razmeroma prijazen vmesnik, je bilo za neposredno učenje uporabe eScriptoriuma zame pomembno tudi obiskovanje poletne šole ATRIUM v Berlinu, ki jo je organizirala DARIAH. Udeležila sem se je skupaj s Saro Vukotić, sodelavko Raziskovalnega centra za humanistiko, ki že ima izkušnje z ročno transkripcijo pisem.
Ta poletna šola mi je pomagala pri obvladovanju več faz raziskovanja: učenju o eScriptoriumu, iskanju ustreznega modela za slovenski jezik, treniranju lastnega modela in preverjanju uspešnosti.
Na poletni šoli smo najprej delali na predobdelavi gradiva, na katerem smo morali kasneje delati. Ker smo s seboj prinesli že pripravljene in predobdelane dokumente, ni bilo posebne potrebe po dodatnem delu na našem gradivu. Smo pa vseeno pridobili izkušnje v OpenCV in se naučili predobdelave fotografij tudi na ta način.
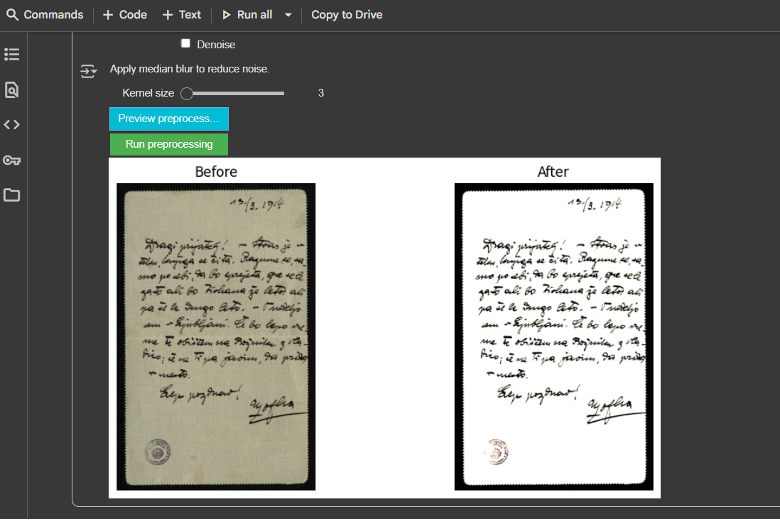
Ko smo imeli pripravljeno in urejeno gradivo, smo se najprej učili osnov segmentacije v eScriptoriumu. Ker je bila kakovost naših faksimilov že precej dobra, je program zelo uspešno samodejno razmejeval regions, lines, masks in polygons. Kljub temu smo pred treniranjem modela popravljali podrobnosti, ki jih je program spregledal, kot so nekoliko prekratke lines ali napačno ločeni regions, kadar smo imeli pisma z več stolpci.

Po uspešni segmentaciji smo testirali že obstoječe in uspešne modele, ki pa so bili trenirani na drugih korpusih, da bi preverili, ali je kateri učinkovit pri branju pisem naših avtoric. Na žalost se je večina dostopnih modelov izkazala za skoraj povsem neuporabne, celo tisti, ki so bili trenirani na sorodnih jezikih, kot sta poljščina ali češčina. Edini model, ki nam je dal vsaj delno pozitivne rezultate, je bil FoNDUE-GD – pri prvem poskusu je prepoznal približno 50 % znakov.


Zato smo se v posvetu s programerji in predavatelji pogovarjali o tem, ali naj treniramo lasten model na novo ali pa naj treniramo FoNDUE, ki je razmeroma uspešno prepoznaval nekatere znake rokopisa. Odločili smo se, da je FoNDUE dobra osnova. Mentorji so nam tudi svetovali, naj se odločimo, da ta model dodatno treniramo samo na enem rokopisu – torej eni avtorici oz. enem avtorju iz zbirke – da bi ga učili na čim bolj specifičnem gradivu.
Padla je odločitev, da v tej fazi delamo samo z Zofko Kveder, saj je bilo v zbirki že na voljo dovolj njenih ročno transkribiranih pisem, s katerimi smo lahko trenirali model.
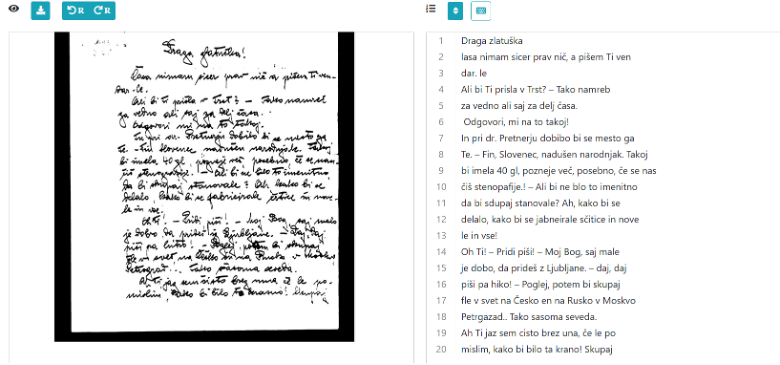
V eScriptoriumu smo najprej izvedle segmentacijo izbranih 20 pisem Zofke Kveder, nato pa smo ročno vnesle že obstoječe transkripte. Zatem smo izvozile podatke (fotografije in transkripte) iz eScriptoriuma in z njimi fine-tunealeFoNDUE-GD. Že po prvem krogu smo model natrenirale na več kot 80 % uspešnosti branja Zofkinih pisem. Po nekaj krogih in z dodatkom novih pisem smo model natrenirali celo na 87 % uspešnosti samodejnega prepoznavanja rokopisnega besedila Zofke Kveder.
Na koncu smo izračunali uspešnost novih natreniranih modelov z izračunom CER (Character Error Rate) in WER (Word Error Rate) s pomočjo že obstoječih orodij, npr. KaMI tool.
Del numeričnih vrednosti uspešnosti prebranih pisem bo kasneje uporabljen v tretji fazi projekta Inspiro 2.0 za programiranje zvoka pisem.
***
S treniranjem modela, ki uspešno bere rokopis Zofke Kveder, se bistveno pospeši proces transkripcije njenih še neprebranih pisem (zlasti denimo v nemščini) in vnos v bazo – kar je eden od dolgoročnih ciljev projekta in celotne prve raziskovalne faze. Model, treniran na rokopisu Zofke Kveder, razmeroma uspešno bere tudi druge rokopise, ki so mu podobni, zato je lahko uporaben za več pisem, ki še čakajo na transkripcijo v prihodnosti. Poleg tega se lahko model, treniran na rokopisih Zofke Kveder, dodatno uri na drugih rokopisih oziroma delih avtorjev in avtoric.
Ker eScriptorium omogoča shranjevanje modelov in njihovo nadaljnjo uporabo, to pomeni, da bomo lahko v prihodnje izdelali modele za večino avtorjev in avtoric v korpusu Pisma, kar dolgoročno olajša vnos novih pisem v bazo.
B) DRUGA FAZA: strojno branje in čustva v pismih
Osnovni cilj druge faze projekta je preveriti povezanost uspešnosti samodejnega branja pisem in morebitno povezanost rezultatov strojnega branja z vsebino pisem, torej z njihovim čustvenim nabojem.
V ta namen sem vnaprej izbrala dve skupini pisem: eno skupino čustveno obarvanih pisem in eno kontrolno skupino. Pisma sem izbrala glede na tematsko kategorizacijo, ki že obstaja na spletni strani pisma.org. Tako so se v »čustveni skupini« znašla pisma, ki obravnavajo teme, kot so: žensko prijateljstvo, prijateljstvo med ženskami in moškimi, moško prijateljstvo, ljubezen, sreča, spolnost, erotika, zakon, domoljubje. V kontrolni skupini pa so pisma, ki pokrivajo naslednje teme: kultura in umetnost, rastlinski svet, običaji in praznovanja, uredniško delo, zdravje, delavnost, politika, gospodarstvo, družabnost, finance, vreme, hrana, gledališče.
V tej fazi sem se najprej osredotočila na pisma Zofke Kveder – zato, ker sem v prejšnji fazi pripravila model za branje njenih rokopisov – vendar sem poskusila preveriti hipotezo o (ne)povezanosti vsebine ter uspešnosti branja tudi pri drugih avtoricah in avtorjih. Tako sem model, izurjen na pismih Zofke Kveder, preizkusila tudi na pismih Marice Nadlišek Bartol in Vide Jeraj.
Metrika: kako določamo uspešnost strojnega branja?
Kot smo že izpostavili v prvi fazi, smo model za branje pisem Zofke Kveder natrenirali do 87 % uspešnosti. Načeloma ta odstotek prikazuje natančnost modela, vendar se konkretna metrika izračunava na posameznih primerih in prikazuje dejansko uspešnost branja.
Metrika se uporablja za oceno, kako uspešno deluje ATR-model – torej, kako zanesljiv in učinkovit je pri pretvarjanju fotografij besedila v natančno digitalno besedilo. Da bi preverili, kako uspešno je model prebral posamezno pismo, uporabimo dva besedila oziroma transkripta: referenčno besedilo (tj. pravilno transkripcijo) in besedilo, pridobljeno s samodejnim branjem. Nato primerjamo ti dve besedili.
Na tej točki je pomembna t. i. Levenštajnova razdalja – metrična operacija, s katero merimo razliko med dvema nizoma in ki pokaže, koliko sprememb je potrebnih, da bi se en niz (denimo en vrstič v pismu) pretvoril v drugega. Ločimo tri vrste sprememb:
- insertion – dodajanje znakov, kjer jih ne bi smelo biti;
- substitution – zamenjava enega znaka z drugim;
- deletion – odstranjevanje oziroma brisanje znakov, kjer bi se morali pojaviti.
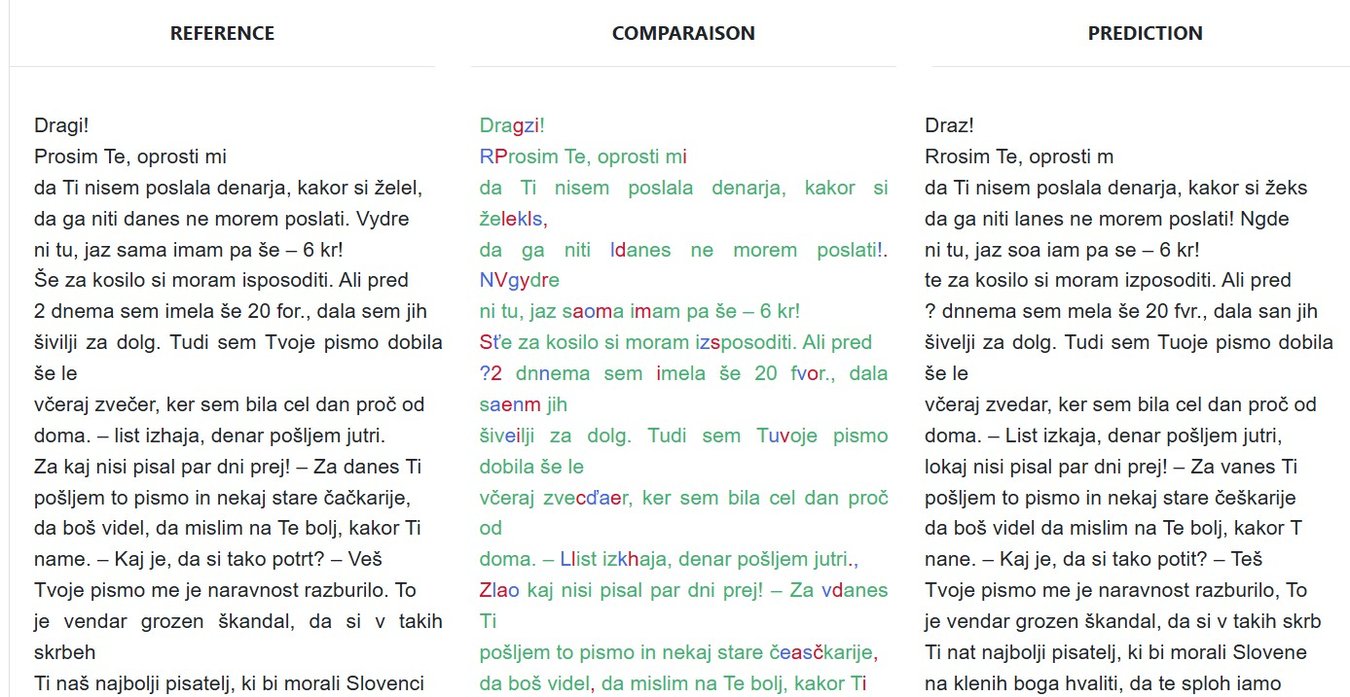
Primer iz enega pisma Zofke Kveder:
- Pravilni niz (referenčno besedilo): Dragi! Prosim Te, oprosti mi, da ti nisem poslala denarja.
- Model: Draz! Rrosim Te, oprosti m da ti nisem poslala denarja.
- Primerjava: Dragzi! RProsim Te, oprosti mi, da Ti nisem poslala denarja.
Z rdečo so označene deletion, z modro pa insertion in substitution. V tem smislu:
- Dragi! → Draz! → 2 napaki (deletion in substitution);
- Prosim → Rrosim → 1 napaka (substitution);
- mi, → m → 2 napaki (deletion).
Levenštajnova razdalja torej znaša 5.
S tem se metrika ne konča. Da bi izračunali t. i. Character Error Rate (CER) – rezultat, ki pokaže natančnost samodejne transkripcije posameznega znaka – moramo število napak deliti s številom znakov v referenčnem (tj. pravilnem) besedilu.
Torej: (Insertion + Deletion + Substitution) / (Num. of Characters in ref.) x 100.
V našem primeru: 5 / 58 = 0.0862 x 100 = 8,62% (CER).
Podobno se izračuna tudi Word Error Rate (WER) – vsota vstavljenih, izbrisanih ali zamenjanih besed, deljena s skupnim številom besed v referenčnem besedilu. Ti rezultati so običajno prikazani v odstotkih.
Torej: (Num. of words with Errors) / (Total num. of words in ref.) x 100.
V našem primeru: 3 / 10 = 0.3 x 100 = 30% (WER).
Da bi se izognili ročnemu izračunavanju, obstajajo različna orodja, ki ta proces pospešijo in rezultate izračunajo samodejno, npr. Kraken as Model Inspector – KaMi, CERberus, Dinglehopper. Za potrebe svojega dela sem uporabila KaMi, ker ima pregleden vmesnik, omogoča izvoz podatkov v csv-obliki in ponuja vizualno primerjavo besedil.
Poleg Levenštajnove razdalje na ravni znakov ali besed ter CER-a in WER-a ta orodja ponujajo še druge uporabne metrike, npr.:
- WACC – Word Accuracy, delež besed brez napake;
- CIL – Character Information Lost;
- CIP – Character Information Preserved.
Za določanje uspešnosti modela pri posameznem pismu sem se oprla predvsem na WACC in CIP.
Obstaja razlika v uspešnosti samodejnega branja med čustveno in kontrolno skupino pisem?
Kratek odgovor je: ne.
Na primeru izbranih pisem Zofke Kveder iz skupine čustveno obarvanih pisem je model ta pisma v povprečju prebral s 84,02 % uspešnostjo (CIP). Najuspešneje prebrano pismo iz te skupine je bilo pismo z ID-jem 645, pri katerem je bilo uspešno prepisanih 84,96 % znakov. Če pogledamo WACC, torej odstotek uspešno transkribiranih celih besed, je model najuspešneje prebral pismo, ki je bilo kot prvo vneseno v bazo Pisma – ID 1 – s 68,75 % pravilno prebranih besed.
V kontrolni skupini pisem je bila uspešnost transkripcije podobna – povprečno 81,24 % (CIP). Najbolje prebrano pismo iz te skupine je v bazo vneseno pod ID 2095, model pa ga je prebral z 83,9 % uspešnostjo prepoznavanja znakov. Enako pismo ima tudi najvišji WACC: 68,2 %.
Tako na primeru Zofkinih pisem skorajda ni razlike med kontrolno in čustveno skupino. To kaže, da v rokopisu Zofke Kveder ni razlik v »berljivosti«, ki bi bile neposredno povezane z vsebino pisma.
V tem smislu se potrjuje domneva, da rokopis Zofke Kveder ni deloval kot sredstvo samocenzure – saj je na enak način pisala tako tehnične informacije kot intimne vsebine; ni torej s spremembo pisave poskušala prikriti ali zakodirati osebnih vsebin. Po drugi strani pa bi lahko to trditev razumeli ravno obratno – kot obliko samokontrole: rokopis Zofke Kveder ni odražal njenih čustev ali sprememb v tonu pisem, temveč je deloval kot sredstvo nadzora in regulacije.

***
V tem kontekstu so zanimiva tudi pisma Marice Nadlišek Bartol in Vide Jeraj. Ker sem poskušala pisma obeh avtoric transkribirati z modelom, natreniranim na pismih Zofke Kveder, je bil rezultat seveda nižji – do te mere, da so bila pisma pogosto neberljiva. Povprečno število ohranjenih znakov (CIP) je bilo v obeh primerih okoli 40 %.
Vendar za to fazo raziskave ni bila odločilna sama uspešnost modela, temveč dejstvo, da razlika med čustveno in kontrolno skupino pisem ne presega 10 %. Čeprav so se vsa pisma gibala okoli omenjenih 40 % CIP, je bilo najuspešneje prebrano pismo Vide Jeraj, v bazo vneseno pod ID 1603, iz kontrolne skupine pisem, pri katerem je bilo ohranjenih 46,67 % znakov.
Uspešnost samodejnega branja je sicer precej padla glede na delež besedila, napisanega v cirilici – saj model ni bil treniran na cirilici.
Primer: pismo Marice Nadlišek Bartol, v bazo vneseno pod ID 604, iz čustvene skupine, vsebuje več vrstic v cirilici. Če te vrstice upoštevamo, program prepozna le okoli 33 % znakov. Če pa cirilične vrstice izločimo (ker model ni bil treniran na to pisavo), je uspešnost branja podobna kot pri ostalih pismih Bartol in Jeraj – 39,7 %.
V tem smislu – če prehod na cirilico razumemo kot obliko cenzure, zlasti v družbeno političnem kontekstu konca 19. in začetka 20. stoletja, ko so ta pisma nastajala – lahko rečemo, da je bila ta cenzura v kontekstu samodejnega (strojnega) branja dejansko uspešna. Vendar je tak zaključek izključno tehničen in potencialno problematičen iz več razlogov:
- Avtorice tistega obdobja si niso mogle predstavljati stroja kot potencialnega bralca intimnih izpovedi, ki bi ga lahko zmedle s prehodom v drugo pisavo
- model je mogoče trenirati tudi na ciriličnih vnosih in ga tako usposobiti za branje teh »cenzuriranih« delov pisem. Prav tako je mogoče kombinirati več modelov na istem besedilu (npr. posebej uporabiti model, treniran na cirilici, za del besedila, napisan s to pisavo);
- raba cirilice v pismih avtoric tega obdobja ni bila dosledna – zato ne moremo trditi, da je šlo za zavestno in premišljeno obliko samocenzure, tudi brez poskusa samodejnega branja.

Kot piše dr. Primož Mlačnik v svojem članku Epistolarne intimnosti: razmerja med pisemskim prijateljstvom, ustvarjalno samocenzuro in žensko emancipacijo, je ena od posebnosti prehajanja med latinico in cirilico v zasebni korespondenci slovenskih pisateljic moderne dvojna nedoslednost: prvič, vsebine, zapisane v cirilici, niso nujno intimne; drugič, enako provokativne in odkrite izjave so pisale tudi v latinici (Mlačnik, 527).
Čeprav Marica Nadlišek Bartol prehaja med pisavama nedosledno (Mlačnik 529), se cirilica pogosto pojavlja v povezavi z bolj intimnimi občutji – denimo z negativnim mnenjem o moških, osebnim odnosom do zakona, izražanjem želje ali ljubezni ipd. (Mlačnik 528) – kar kaže na delno in občasno povezanost pisave z vsebino.
Kot Mlačnik povzema, je »abecedni prehod med latinico in cirilico mogoče razumeti kot obliko implicitne, a deloma neuspešne samocenzure – pisateljice so ga uporabljale kot sredstvo skrivanja čustev in govora o intimnih stvareh« (Mlačnik 533). Po drugi strani Mlačnik trdi, da je nedosledna uporaba tega prehoda jasno izražala upor proti cenzuri in družbenim pritiskom (Mlačnik 535).
Vendar tega pojava ne bi nujno imenovala »upor«, saj ta izraz predpostavlja zavestno odločitev za določeno strategijo – naključnost in nedoslednost pri prehodu iz latinice v cirilico delujeta prej kot nezanimanje za družbeni pritisk. Podobno lahko rečemo tudi za sam rokopis (ne glede na pisavo) – kot so pokazali rezultati, rokopis sam ne razkriva čustev, torej se ne spreminja glede na vsebino pisma.
Kot smo že omenili, lahko to dejstvo razumemo na dva načina:
- avtorice so enako odprto pisale o intimnih in vsakdanjih temah (odpor proti cenzuri, ali nezanimanje za normo);
- z uporabo enake pisave so nadzorovale izražanje čustev, ki bi se sicer razkrila ob natančnem branju vsebine.
Kako zvenijo pisma?
V tretji in končni fazi projekta empirične rezultate iz prvih dveh faz prenašam v drugo dimenzijo – zvok – z namenom predstaviti (ne)berljivost pisem v mediju, ki je drugačen od besedila. Na ta način raziskava prehaja skozi večmedijske transformacije: najprej iz slike (skeniranih pisem) v besedilo, nato iz besedila v zvok. Čeprav je začetna hipoteza predvidevala razliko med čustvenimi pismi in kontrolno skupino pisem, se je – kot je pokazala druga faza raziskave – izkazalo naslednje: model pisma bere enako (ne)uspešno, ne glede na njihovo vsebino ali čustveni naboj.
Kot je pokazala prejšnja faza raziskave, metrični rezultati ne variirajo bistveno glede na to, ali se nanašajo na čustveno ali kontrolno skupino pisem, zato tudi zvok, programiran na podlagi teh metrik, ne more prenesti razlik v čustvenem intenzitetu pisem. Po drugi strani je zvočnost pridobila nov pomen – kot komentar razmerja med intimnostjo pisem in povsem tehničnim, strojnim branjem. Diskrepanca med osebnimi pismi na eni strani in javno dostopnim modelom samodejnega branja na drugi se zdaj prenaša v robotsko generiran zvok. V tem smislu, tako kot model, ki pisma bere enako uspešno ne glede na njihovo vsebino, tudi zvok enako mehanično prenaša to indiferentnost. V nadaljevanju bom nekoliko podrobneje pojasnila proces kodiranja zvoka pisem, skupaj s primeri.
***
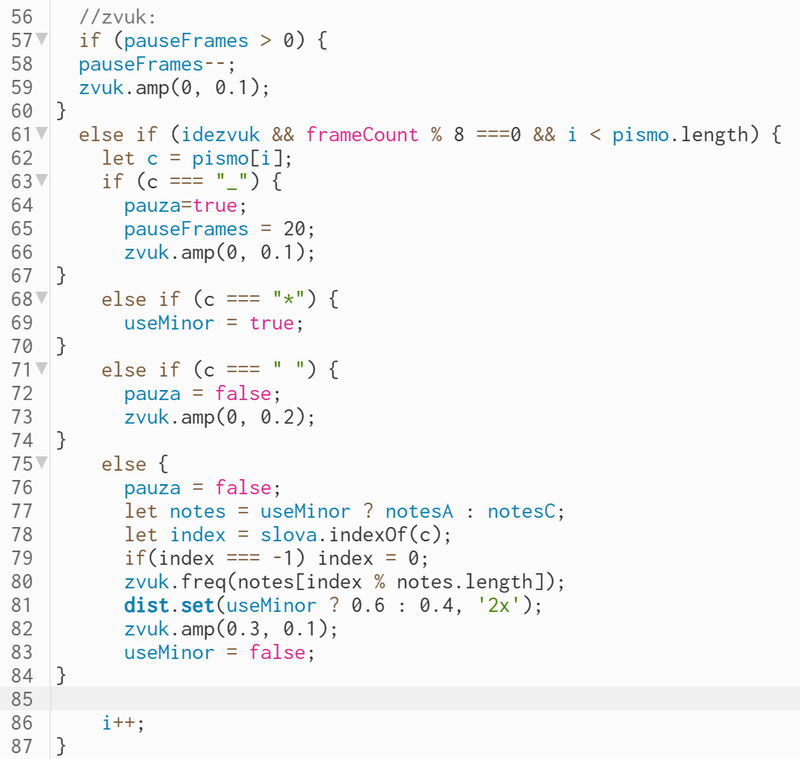
Kot rezultat te faze projekta sem ustvarila zvočne posnetke, ki ponazarjajo razlike med (ne)uspešnimi transkripcijami, s poudarkom na tem, kar je bilo v procesu transkripcije izpuščeno ali dodano v besedilo. Vsako pismo ima svoj »zvok« glede na stopnjo uspešnosti transkripcije. Za to fazo sem se odločila delati v programu p5.js – odprtokodni in uporabniku prijazni knjižnici za JavaScript, namenjeni ustvarjalnemu programiranju in digitalni umetnosti.
Dodatno, p5.js vključuje tudi zvočno knjižnico p5.sound, ki omogoča manipulacijo obstoječih zvočnih posnetkov in sintezo novih zvokov z uporabo oscilatorjev – funkcij, ki ustvarjajo zvočne valove. Te valove sem oblikovala glede na njihovo jakost, frekvenco in obliko, z ustreznimi zvočnimi filtri, tako da ima vsak znak pisma svoj poseben zvok.
Moja začetna zamisel je bila, da se – glede na besedilo – različni toni izmenjujejo s tišino in/ali neprijetnim šumenjem, kar bi ilustriralo nezmožnost razumevanja in (ne)uspešnost transkripcije. Začetna ideja se je nato v procesu dela in ob mentorskem vodenju postopno prilagodila, kot bo prikazano v nadaljevanju.
Prva različica kode
Osnove prenosa besedila v zvok v p5.js-u:
1. Uspešno transkribirani znaki so povezani z različnimi notami, tako da je vsak znak preslikan v določeno frekvenco (ki se giblje vzdolž C-dur lestvice, od 261.63 Hz do 493.88 Hz). Na primer, vsaka črka »a«, ki se pojavi v besedilu, zveni na en način, vsaka »n« pa na drug.
2. Znaki, ki jih je model izpustil med transkripcijo (deletion), so označeni z znakom »_« in zvenijo kot izrazita pavza v branju.
3. Znaki, ki jih je model dodal med transkripcijo (insertion), so označeni z znakom »*« in zvenijo kot šum oziroma noise.
4. Znaki, ki jih je model zamenjal (substitution), so obravnavani kot kombinacija brisanja pravilne črke (deletion) in dodajanja nove (insertion).
V kodi je to doseženo z if statement – pogojnim stavkom, ki določa tip znaka in glede na to generira ustrezen zvok (ton, tišino ali šum).
Hitrost zvoka je modelirana glede na povprečno hitrost branja – približno 238 besed na minuto, tj. 900–1000 znakov na minuto, kar ustreza približno 15 prebranim znakom na sekundo. Ker koda privzeto bere 60 znakov na sekundo (60 frames per second / FPS), sem prilagodila menjavanje sličic, da sem branje upočasnila: vsak četrti frame sproži nov zvok (skupno 15 na sekundo). Ker bi s takšnim tempom branje celotnega pisma trajalo predolgo, sem za ustvarjanje zvoka izbrala uvodne odlomke pisem, da posnetki ne bi bili predolgi.
Generirani zvok je dodatno oblikovan z učinki distortion, noise, reverb in delay. Distortion in noise ustvarjata vtis popačenega zvoka in prasketanja pri napačno transkribiranih črkah – kot zvočna ilustracija »šuma« v komunikaciji oziroma nezmožnosti sporazumevanja. Reverb in delay pa ustvarjata občutek prostornosti in odmeva pri pravilno prebranih tonih, kar nakazuje:
a) branje pisem na glas ter
b) da tisto, kar slišimo, morda ni popolnoma zvesto izvirniku.
Podvodni učinek, ki pri tem nastane, ustvarja vtis zadušenosti in spominja na tisto, kar je neizogibno izgubljeno v »prevodu«, ko gre za odnos med čustveno nabitimi, ročno pisanimi, zasebnimi korespondencami in avtomatiziranim procesom njihove transkripcije.
Dodatek osnovnemu zvoku predstavlja t. i. noise slider, ki generiranemu zvoku dodaja sloj »šuma« glede na izračunan odstotek uspešnosti transkripcije. Kadar je transkripcija uspešnejša, je količina šuma manjša – in obratno (primere glej spodaj).
Druga različica kode
Na podlagi sugestije prof. Perovška, da bi bilo treba tudi sam šum – tj. napako pri branju – zvočno opredeliti, sem spremenila kodo.
V prvi različici so napake dodanih črk (insertion) in zamenjav (substitution) zvenele kot šum, v drugi različici pa smo te napake – napačne znake – nadomestili s toni vzdolž a-mol lestvice (vzporedne lestvice C-dura). Pravilno transkribirani znaki zdaj v končni različici ustrezajo notam C-dur lestvice, dodani znaki pa zvenijo v a-molu.
Komponenta šuma je ostala prisotna v noise sliderju, kot dodatna plast zvoka.
V tej fazi sem glede na prvo različico dodala tudi nove znake, ki ustrezajo slovenski abecedi, saj sem prvo verzijo pripravila s črkami angleške abecede. Tako je bila transkripcija natančneje določena.
Prilagoditev besedila
Da bi p5.js pravilno prebral besedilni niz in glede nanj generiral zvok, je bilo treba dobljena transkribirana besedila prevesti v ustrezno obliko. Za generiranje zvoka sem najprej uporabila krajše odlomke iz začetka transkribiranih pisem – verzijo, ki vsebuje pravilno transkribirane, izpuščene in dodane znake:

Z zeleno so označene pravilno transkribirane črke in ločila, z rdečo izpuščeni znaki, z modro pa znaki, ki jih je model sam (napačno) dodal.
Zato rdeče črke zamenjam z oznako »_«, modre pa z »*«. Razmik med besedami ohranim kot » «. Vrstice sem morala odstraniti, saj p5.js lahko bere le enoten string; prehodi med vrsticami so zato označeni z dvojnim presledkom » «.
Primer:
v.1: "Dra_*_! *_rosim Te, oprosti m_ da Ti nisem poslala denarja, kakor si že__*_*_ da ga niti *_anes ne morem poslati*_ *_*_d_e ni tu, jaz s_*_a i_am pa še – 6 kr! _**e za kosilo si moram i*_posoditi. Ali pred *_ dn*ema sem _mela še 20 f*_r., dala s*_*_ jih šiv*_lji za dolg."
V drugi različici kode je bilo treba prilagoditi vlogo znaka »*«. Namesto da bi v celoti nadomestil črko (s šumom), ta znak zdaj v kodi označuje spremembo notne lestvice. Nova različica torej ohranja dodane črke, pred katerimi stoji znak »*«:
v.2: "Dra_*z_! *R_rosim Te, oprosti m_ da Ti nisem poslala denarja, kakor si že__*k_*s_ da ga niti *l_anes ne morem poslati*!_ *N_*g_d_e ni tu, jaz s_*o_a i_am pa še – 6 kr! _*t*’e za kosilo si moram i*z_posoditi. Ali pred *?_ dn*nema sem _mela še 20 f*v_r., dala s*a_*n_ jih šiv*e_lji za dolg.
Koda – osnovne funkcije in mehanizem
p5.js koda je sestavljena iz več celin.
V prvi deklariramo spremenljivke (variables), tj. mesta v pomnilniku, ki dobijo ime (s funkcijo let) in začetno vsebino (npr. besedilni niz, številčno vrednost, niz števil, logično vrednost). Deklaracija spremenljivke je nujna, da jo lahko kasneje uporabimo.
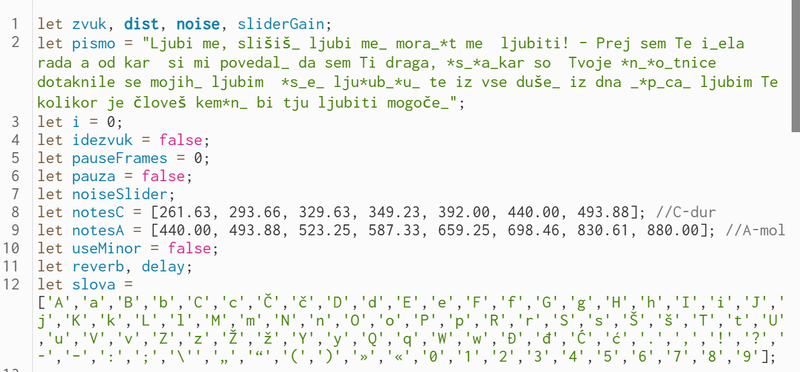
Nato sledita glavni funkciji kode v p5.js: setup in draw. V setup zapišemo vse, kar se med izvajanjem kode ne spreminja – pripravljalne postopke za delovanje funkcije draw. Draw je del kode, ki se izvaja 60-krat na sekundo; vse, kar je v njem zapisano, se nenehno izvaja in briše po vrstnem redu, kot je zapisano.
- function setup()
V delusetup ustvarimo določene objekte (Oscillator) in učinke (Distortion, Noise, Reverb, Delay), ki se aktivirajo v funkciji draw. Z oscilatorjem določimo obliko valov (sine, triangle, square, sawtooth), jakost (amp – amplitudo od 0 do 1) in višino tona (freq – frekvenco v Hz). Efekt distortion modulira ustvarjeni val (oscilator), tj. vpliva na njegovo pravilnost. Uporabljamo ga za šum, skupaj z noise, ki je lahko »white«, »pink« ali »brown«, kar daje različne zvočne teksture. Vse to je treba povezati z glavno spremenljivko sound, v kateri shranjujemo objekt oscilatorja.

- function draw()
Znotraj funkcije draw znaki pisma dobijo svoj zvočni izraz preko if statement, ki preverja tip znaka – pravilno zapisan, izpuščen, dodan ali presledek. Ko program določi ustrezni pogoj, nadaljuje na naslednji znak in ponavlja zanko (loop) vse do konca besedila.
Primeri in rezultati
Kot rezultat opisanega procesa bom predstavila nekaj primerov.
Najprej, na primeru uvodnih vrstic pisma Zofke Kveder, vnesenega v bazo pod ID-1, katere metriko sem predstavila v drugi fazi projekta, prva faza kodiranja (črka: zvok v C-dur, napaka: šum) je zvenela takole:
Mentor prof. Boštjan Perovšek je predlagal, da bi bilo treba tudi samo napako zvočno opredeliti – kar se je izkazalo za zelo dobro sugestijo, saj smo v prejšnji fazi pokazali, da obstajajo različne vrste napak (substitution, deletion, insertion). Ker ima vsaka črka določeno frekvenco, je mentor predlagal, da bi namesto šuma napačne črke pretvorila v toni druge, a-mol lestvice.
Po tej spremembi isto pismo zveni takole:
Kot sem že omenila, zvok teh pisem ne prenaša neposredno njihovega čustvenega potenciala, saj model pisma bere enako uspešno, ne glede na njihovo vsebino. Ker je mehanizem umetniške transformacije predvsem neposreden prenos med mediji, sem poskušala vplivati na interpretacijo – torej estetski sloj zvoka – z modifikacijo značilnosti valov in filtrov ter z izbiro tistih delov pisem, ki zaradi ponavljanj, asonanc in aliteracij zvenijo prijetneje.
Rezultat je naslednji:
V primerjavi z navedenimi pismi – ki jih je model uspešno prebral – pisma Vide Jeraj in Marice Nadlišek Bartol vsebujejo veliko več napak in zvenijo takole:
Ti posnetki in še drugi primeri ozvočenih pisem – vključno s posnetki, prek katerih je dodan sloj noise-a, ki ustreza koeficientu uspešnosti transkripcije – so dostopni na SoundCloud profilu projekta preko povezave: https://soundcloud.com/ems-445338857/sets/kako-zveni-neberljivost-custev?si=eacc86e84ed248c4acc3f677ef2aef37&utm_source=clipboard&utm_medium=text&utm_campaign=social_sharing
Interpretacija rezultatov tretje faze
Rezultate tretje faze projekta je mogoče razlagati na dva, medsebojno neizključujoča načina:
- Dobljeni – robotski in brezosebni zvok – ustrezno prenaša proces mehanizacije in mašinizacije intimne korespondence pisateljic moderne ter prikazuje, kako metode digitalne humanistike, prenesene na literaturo, potencialno razosebijo čustveni sloj, ki nas prvotno pritegne k tem umetniškim delom. V tem smislu neprijetnost samega zvoka skoraj dobesedno posreduje sporočilo o odtujenosti procesa strojnega branja od vsebine pisem – o indiferentnosti modela do besedila.
- Po drugi strani lahko rezultate razumemo tudi kot kreativna izhodišča z vmesnimi produkti, ki bodo služili kot material za nadaljnjo kreativno gradnjo. Delo na obstoječih rezultatih bi tako potekalo v smeri nadaljnjih intervencij – torej dodatne estetizacije zvoka z namenom, da bi se ponovno prebudila osnovna čustva prebranih pisem. Na ta način lahko rezultate, do katerih sem prišla, razumemo kot osnutek bodočega umetniškega dela oziroma kot smernice za prihodnji razvoj projekta.
Študentka: Emilija Vučićević (magistrski študijski program Humanistični študiji, 2. letnik)
Mentorica: doc. dr. Ivana Zajc
Mentor umetniškega dela: Boštjan Perovšek
Delo na interdisciplinarnem umetniško-raziskovalnem projektu temelji na elektronski zbirki Pisma, ki nastaja na Raziskovalnem centru za humanistiko Univerze v Novi Gorici. Glavna urednica zbirke je dr. Katja Mihurko.
Univerza v Novi Gorici s projektom INSPIRO 2.0 odpira vrata raziskovalnega sveta študentom iz vse Slovenije. Namen projekta je izbrati najboljše ideje študentskih projektov in jim omogočiti, da zaživijo v praksi. Projekt financira Ministrstvo za izobraževanje, znanost in šport Republike Slovenije.









